
Η πολυνομία και η συχνή τροποποίηση των νομοθετικών κειμένων καθιστούν δύσκολη την πρόσβαση στη νομοθεσία. Προκειμένου να υπερκεραστεί αυτή η δυσκολία και να απλοποιηθεί η διαδικασία αναζήτησης και εύρεσης νομοθετικών κειμένων με όλες τις τροποποιήσεις τους, διεξάγεται ερευνητική εργασία από το Πανεπιστήμιο Πατρών με την ανάπτυξη ενός ημι-αυτοποιημένου συστήματος για τoν εντοπισμό, την ανάλυση και την εφαρμογή των τροποποιήσεων στα κείμενα των νόμων.
Η έρευνα πραγματοποιείται στο τμήμα Μηχανικών Η/Υ και Πληροφορικής του Πανεπιστήμιου Πατρών από τον μεταπτυχιακό φοιτητή Κωνσταντίνο Πλέσσα υπό την επίβλεψη του Καθηγητή Ιωάννη Γαροφαλάκη και του μεταδιδακτορικού ερευνητή Αθανάσιου Πλέσσα. Η έρευνα έχει ήδη οδηγήσει σε τρεις επιστημονικές δημοσιεύσεις σε διεθνή συνέδρια.
Πώς πήρατε την πρωτοβουλία για να δημιουργήσετε την εφαρμογή OpenlawsGR;
Στη χώρα μας η πρόσβαση στη νομοθεσία είναι συχνά μια πολύπλοκη διαδικασία λόγω της πολυνομίας και των συχνών τροποποιήσεων των νομοθετικών κειμένων. Εάν κανείς θελήσει να βρει την ισχύουσα έκδοση ενός νόμου, χρειάζεται να εντοπίσει όλες τις τροποποιήσεις του που έχουν ψηφιστεί και να τις εφαρμόσει σειριακά στο αρχικό κείμενο του νόμου. Η διαδικασία αυτή είναι γνωστή ως ενοποίηση (consolidation) και είναι ιδιαίτερα απαιτητική διανοητικά για τον αναγνώστη, ο οποίος συχνά δεν μπορεί να είναι βέβαιος αν έχει παραλείψει κάποια τροποποίηση. Υπάρχουν, βέβαια, νομικές βάσεις που προσφέρουν πρόσβαση στο ενοποιημένο κείμενο των νομοθετημάτων, αλλά συνήθως απαιτούν συνδρομή. Αποσπασματικά, μπορεί να βρει κανείς ενοποιημένα νομικά κείμενα σε ιστοσελίδες υπουργείων και άλλων φορέων.
Πότε ξεκίνησε το εγχείρημα;
Το εγχείρημα πραγματοποιήθηκε στα πλαίσια μεταπτυχιακής διπλωματικής εργασίας και ξεκίνησε στις αρχές του καλοκαιριού του 2015. Πρόκειται για μια ιδέα που έχει υλοποιηθεί και σε άλλες χώρες, με πιο γνωστή περίπτωση αυτή της Γερμανίας με το σύστημα Bundesgit. Διαπιστώθηκε, λοιπόν, ότι υπήρχε αυτό το κενό στη χώρα μας όσον αφορά την πρόσβαση των πολιτών στη νομοθεσία, ενώ είχε και ερευνητικό ενδιαφέρον καθώς οι προσπάθειες ανάλυσης των γλωσσικών προτύπων των ελληνικών νομοθετικών κειμένων και της εξαγωγής μεταδεδομένων και πληροφορίας για τη δομή τους είναι ελάχιστες.
Σε ποιο στάδιο βρίσκεστε τώρα;
Αυτή την περίοδο προσπαθούμε να βελτιώσουμε αδυναμίες του συστήματος, καθώς και τα σφάλματα στα επίσημα κείμενα των νόμων που οδηγούν σε λάθη στους 320 νόμους που έχουμε στο αποθετήριο. Το κυριότερο πρόβλημα είναι πως στους υπόλοιπους νόμους για τους οποίους δεν έχουμε καταφέρει να καθορίσουμε τα δομικά τους στοιχεία, υπάρχουν ενδεχομένως τροποποιήσεις προς αυτούς τους 320 νόμους τις οποίες, όμως, το σύστημα αγνοεί και επομένως δεν εφαρμόζει. Στο blog μας έχουμε δημοσιεύσει ένα roadmap με τις βελτιώσεις που θα θέλαμε να κάνουμε για να κυκλοφορήσει μια Beta έκδοση του συστήματος. Οπότε ευελπιστούμε, όταν γίνει αυτό, να έχουμε στο αποθετήριο όλους τους νόμους της περιόδου 2004-2015 με όσο το δυνατόν λιγότερα λάθη. Σε επόμενο στάδιο μας ενδιαφέρει η δημοσίευσή τους σε κάποιο XML πρότυπο, όπως το Akoma Ntoso.
Πόσο καιρό διήρκησε η διαδικασία ώστε να δημιουργηθεί το αποθετήριο με τους 320 νόμους;
Η διαδικασία διήρκεσε περίπου έναν χρόνο. Όμως, θα πρέπει να λάβει κανείς υπόψη του ότι η υλοποίηση έγινε στο μεγαλύτερο μέρος της από ένα άτομο, το οποίο εργαζόταν ταυτόχρονα. Επομένως, μια μεγαλύτερη ομάδα πλήρους απασχόλησης θα μπορούσε να φτάσει στο ίδιο σημείο αρκετά πιο σύντομα.
Θα μπορούσατε να μας πείτε τι έχει γίνει μέχρι στιγμής;
Στο πλαίσιο της έρευνας έχει υλοποιηθεί ένα ημι-αυτοματοποιημένο σύστημα για τoν εντοπισμό, την ανάλυση και την εφαρμογή των τροποποιήσεων στα κείμενα των νόμων. Η προσέγγιση στην οποία βασίστηκε ονομάζεται ταίριασμα προτύπου (pattern matching) με τη χρήση κανονικών εκφράσεων (regular expressions). Καθώς η νομική γλώσσα είναι σχετικά δομημένη, μπορούν να εντοπιστούν επαναλαμβανόμενα πρότυπα που χρησιμοποιούνται για να δηλώσουν τη δομή των νομοθετικών κειμένων και τις τροποποιήσεις (π.χ. μετά από κάθε άρθρο υπάρχει το νούμερό του και προαιρετικά ο τίτλος του, ενώ στην περίπτωση των αντικαταστάσεων χρησιμοποιείται κάποιο ρήμα που δηλώνει αντικατάσταση ακολουθούμενο από κείμενο σε εισαγωγικά). Οι ερευνητές έχουν μοντελοποιήσει τους κανόνες της ελληνικής νομοθεσίας με τη μορφή προτύπων, η παρουσία των οποίων αναζητείται στα κείμενα των νόμων. Το σύστημα, που ονομάζεται OpenlawsGR, έχει αναπτυχθεί με τεχνολογίες ανοικτού κώδικα και υλοποιεί τα παρακάτω βήματα:
- Μεταφόρτωση των PDF αρχείων από τα τεύχη Α’ της Εφημερίδας της Κυβερνήσεως με το σύνολο των νόμων.
- Μετατροπή των PDF αρχείων σε απλό κείμενο.
- Διαχωρισμός νόμων από άλλα νομοθετήματα (π.χ. Προεδρικά Διατάγματα, Υπουργικές Αποφάσεις).
- Προεπεξεργασία κειμένου για τη διόρθωση σφαλμάτων που υπεισέρχονται στα προηγούμενα βήματα.
- Δομική ανάλυση νόμων. Σε αυτό το βήμα αναγνωρίζονται τα δομικά στοιχεία των νόμων, όπως άρθρα, παράγραφοι κ.λπ.
- Έλεγχος εγκυρότητας και χειροκίνητες διορθώσεις. Συχνά, λάθη στο κείμενο των νόμων (π.χ. ορθογραφικά, συντακτικά, μη συμμόρφωση με τους κανόνες σύνταξης νομοθεσίας) έχουν ως αποτέλεσμα σφάλματα στη δομική ανάλυση των νόμων. Σε αυτό το βήμα εντοπίζονται αυτές οι περιπτώσεις και διορθώνονται χειροκίνητα.
- Εντοπισμός, ανάλυση και εφαρμογή των τροποποιήσεων που έχει υποστεί κάθε νόμος στο κείμενό του.
- Αποθήκευση των διαφορετικών εκδόσεων κάθε νόμου σε ένα αποθετήριο στο σύστημα ελέγχου αναθεωρήσεων Github.
Μπορείτε να μας δώσετε μια σύντομη περιγραφή της διαδικασίας που θα ακολουθήσει κάποιος στην εφαρμογή σας, προκειμένου να εντοπίσει αυτό που αναζητά;
Ας υποθέσουμε ότι ο/η χρήστης ενδιαφέρεται για κάποιον συγκεκριμένο νόμο και το ιστορικό αλλαγών που έχουν γίνει σε αυτόν, π.χ. τον 3231/2004. Μπορεί να εντοπίσει τον νόμο στο αποθετήριο και να δει την τρέχουσα έκδοσή του. Στη συνέχεια. μπορεί να δει το ιστορικό αλλαγών:
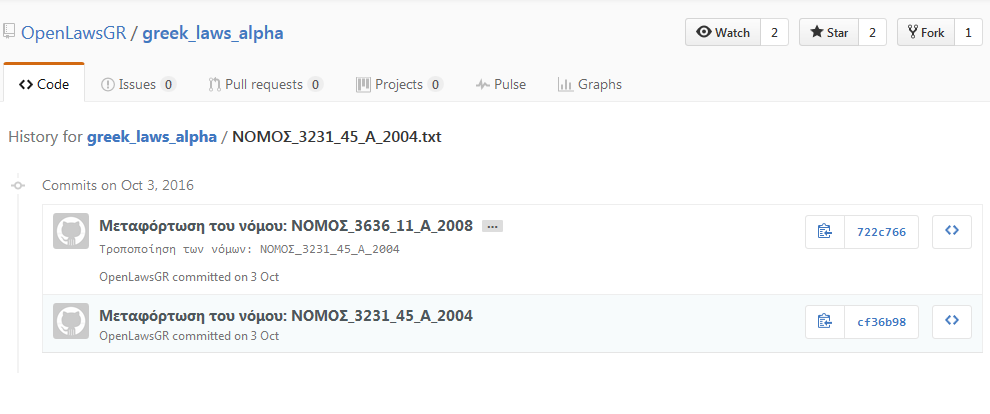
Σε αυτή την περίπτωση, θα διαπιστώσει ότι μετά την αρχική δημοσίευση του νόμου, αυτός έχει τροποποιηθεί μια φορά από τον Ν. 3636/2008. Έπειτα, έχει τη δυνατότητα να δει πώς διαμορφώνεται κάθε αναθεώρηση του κειμένου του νόμου. Τέλος, αν το επιθυμεί μπορεί να δει οπτικά τι έχει αλλάξει:
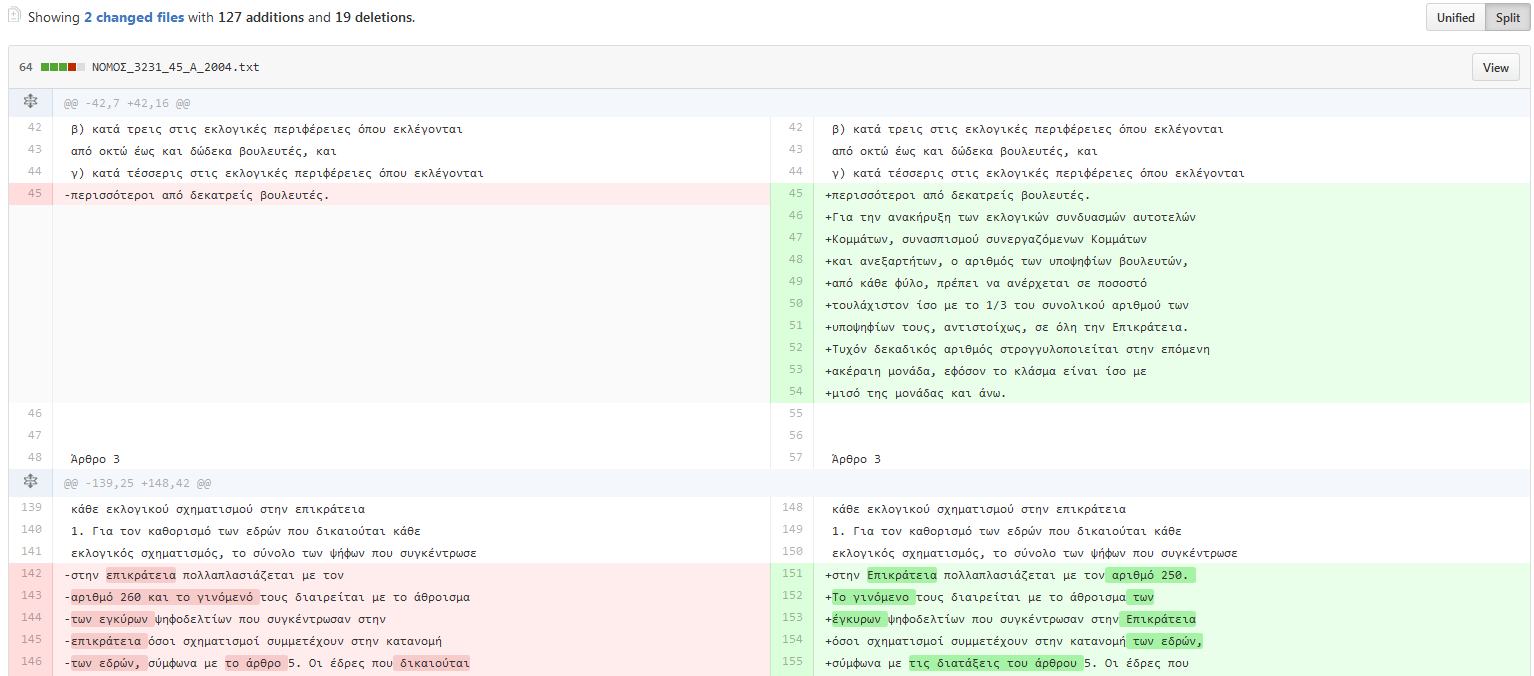
Ποια είναι τα σημαντικότερα προβλήματα τα οποία εντοπίσατε κατά τη διάρκεια της εργασίας σας;
Κατά την ανάπτυξη του συστήματος υπήρξε ανάγκη να ξεπεραστούν σημαντικά προβλήματα της νομοθετικής διαδικασίας που ακολουθείται στη χώρα μας: απουσία API ή Web Service για τη μεταφόρτωση της νομοθεσίας, αρχεία σε μη μηχανικώς αναγνώσιμο μορφότυπο, απουσία χρήσης προτύπων (π.χ. XML πρότυπα), συντακτικά λάθη στα κείμενα και μη συμμόρφωση με τους κανόνες σύνταξης νόμων της Κεντρικής Νομοπαρασκευαστικής Επιτροπής (ΚΕ.Ν.Ε.) κ.α. Οι δυσκολίες αυτές καθιστούν πρακτικά αδύνατη την υλοποίηση ενός πλήρους αυτοματοποιημένου συστήματος, με αποτέλεσμα να απαιτείται η ανθρώπινη παρέμβαση στο βήμα 5, καθώς όλα τα υπόλοιπα βήματα είναι πλήρως αυτοματοποιημένα.
Πώς επιλύθηκαν αυτές οι δυσκολίες;
Ένα σημαντικό μέρος της υλοποίησης (βήματα 1-4 της αρχιτεκτονικής του συστήματος) αφιερώθηκε στην αντιμετώπιση δυσκολιών που προέρχονται από την ελλιπή αξιοποίηση της τεχνολογίας στη διαδικασία παραγωγής της νομοθεσίας στη χώρα μας. Καθώς δεν υπάρχει κάποιο API ή Web Service που να επιτρέπει τη μαζική λήψη των Φ.Ε.Κ. από το Εθνικό Τυπογραφείο, δημιουργήθηκε ένας crawler (δηλαδή ένα πρόγραμμα που διαβάζει τις σχετικές ιστοσελίδες και αυτόματα εντοπίζει και κατεβάζει τη ζητούμενη πληροφορία) που πραγματοποίησε αυτή τη διαδικασία. Επίσης, τα Φ.Ε.Κ. δημοσιεύονται ως PDF αρχεία, ένα κλειστό πρότυπο που δεν είναι μηχανικώς αναγνώσιμο και επομένως έπρεπε να μετατραπούν σε απλό κείμενο. Αυτή η μετατροπή ήταν μια διαδικασία που εισήγαγε στα τελικά αρχεία περιεχόμενο που δεν αφορά το κείμενο του νόμου, αλλά την παρουσίαση στο PDF (π.χ. αρίθμηση των σελίδων, επικεφαλίδες και υποσέλιδα κ.α.) και τα οποία έπρεπε να αφαιρεθούν. Μάλιστα, για την πρακτική δημοσίευσης νομικών κειμένων σε PDF υπάρχει και ένα σύντομο μανιφέστο από το Open Law Lab. Τέλος, ακόμα και στα δημοσιευμένα PDF αρχεία υπήρχαν προβλήματα που έπρεπε να λύσουμε, όπως θέματα που αφορούσαν την κωδικοποίηση των χαρακτήρων. Ακόμα, πάντως, δεν έχουμε καταφέρει να βρούμε λύση στο πρόβλημα των σκαναρισμένων σελίδων που εμφανίζονται σε αρκετά PDF αρχεία.
Ποιες εξ αυτών των δυσκολιών θεωρείτε πιο χρονοβόρες ως προς την επίλυσή τους;
Η πιο δύσκολη και χρονοβόρα διαδικασία επίλυσης προβλήματος είναι ο εντοπισμός και η μη αυτόματη διόρθωση σφαλμάτων στο πρωτότυπο κείμενο των νόμων. Τέτοια σφάλματα μπορεί να περιλαμβάνουν ανάμεσα στ’ άλλα:
- Λανθασμένη αρίθμηση στα δομικά στοιχεία των νόμων (π.χ. η επόμενη παράγραφος μετά την παράγραφο 2 να αριθμείται με το 4 αντί για το 3).
- Εισαγωγικά που ανοίγουν αλλά δεν κλείνουν.
- Σημεία στίξης χωρίς κενό από την επόμενη λέξη.
- Ύπαρξη λατινικών χαρακτήρων στο κείμενο που οπτικά είναι ίδιοι με χαρακτήρες του ελληνικού αλφαβήτου (π.χ. τα γράμματα Ν,Ο,Μ,Ο στη λέξη ΝΟΜΟΣ), αλλά καθιστούν τη διαδικασία ταιριάσματος προτύπου ανεπιτυχή.
- Γραφή που δεν ακολουθεί τα πρότυπα σύνταξης νόμων που έχει θέσει η Κεντρική Νομοπαρασκευαστική Επιτροπή.
Για τον εντοπισμό τους έχουμε υλοποιήσει ελέγχους σε μια σειρά από κανόνες επικύρωσης. Το χρονοβόρο κομμάτι είναι η μη αυτόματη διόρθωση των σφαλμάτων αυτών σε όσους νόμους εντοπίζονται.
Σε ποιο στάδιο βρίσκεστε τώρα;
Αυτή την περίοδο προσπαθούμε να βελτιώσουμε αδυναμίες του συστήματος, καθώς και τα σφάλματα στα επίσημα κείμενα των νόμων που οδηγούν σε λάθη στους 320 νόμους που έχουμε στο αποθετήριο. Το κυριότερο πρόβλημα είναι πως στους υπόλοιπους νόμους για τους οποίους δεν έχουμε καταφέρει να καθορίσουμε τα δομικά τους στοιχεία, υπάρχουν ενδεχομένως τροποποιήσεις προς αυτούς τους 320 νόμους τις οποίες, όμως, το σύστημα αγνοεί και επομένως δεν εφαρμόζει. Στο blog μας έχουμε δημοσιεύσει ένα roadmap με τις βελτιώσεις που θα θέλαμε να κάνουμε για να κυκλοφορήσει μια Beta έκδοση του συστήματος. Οπότε ευελπιστούμε, όταν γίνει αυτό, να έχουμε στο αποθετήριο όλους τους νόμους της περιόδου 2004-2015 με όσο το δυνατόν λιγότερα λάθη. Σε επόμενο στάδιο μας ενδιαφέρει η δημοσίευσή τους σε κάποιο XML πρότυπο, όπως το Akoma Ntoso.
Η εφαρμογή πότε θα είναι διαθέσιμη στο κοινό;
Μια πιλοτική εφαρμογή για 320 νόμους από το 2004 έως το 2015 είναι διαθέσιμη στο αποθετήριο https://github.com/OpenLawsGR/greek_laws_alpha. Εκεί, ο χρήστης μπορεί να δει την ισχύουσα έκδοση για κάθε νόμο, να πλοηγηθεί στις προηγούμενες εκδόσεις του και να δει οπτικά τις αλλαγές που έχει επιφέρει κάθε τροποποίηση. Ο κώδικας του συστήματος (σε γλώσσα Python) διανέμεται ελεύθερα από το αποθετήριο https://github.com/OpenLawsGR/greek_laws_consolidation_code.
Όπως προαναφερθηκε, ο κώδικας του συστήματος είναι και τώρα διαθέσιμος στο Github. Η ανάπτυξη θα συνεχίσει να γίνεται εκεί, οπότε και οι επόμενες εκδόσεις θα είναι διαθέσιμες από το ίδιο αποθετήριο. Φυσικά, όποιος/α επιθυμεί μπορεί να τον κατεβάσει, να τον βελτιώσει και να συνεισφέρει στο εγχείρημα. Το ίδιο ισχύει και για το αποθετήριο όπου αποθηκεύονται οι εκδόσεις των νόμων, επομένως και οι διορθώσεις λαθών στα κείμενα θα δημοσιεύονται στο Github.
Ποιος είναι ο τελικός σκοπός αυτού του εγχειρήματος;
Πέρα από το ερευνητικό κομμάτι που μας ενδιαφέρει, καθώς κινούμαστε στον ακαδημαϊκό χώρο, ένας βασικός σκοπός είναι να δείξουμε πώς μπορεί η τεχνολογία να εκσυγχρονίσει τη νομοθετική διαδικασία, να την κάνει πιο διαφανή και να βελτιώσει την πρόσβαση για τους πολίτες, αλλά και για τους δημόσιους οργανισμούς για τους οποίους παρατηρείται το αντιφατικό φαινόμενο να ξοδεύουν χρήματα σε συνδρομητικές υπηρεσίες για την πρόσβαση σε πληροφορία που το ίδιο το κράτος έχει παραγάγει. Ελπίζουμε να βοηθήσουμε στην κινητοποίηση των αρμόδιων φορέων για την ανάληψη δράσης για την εφαρμογή ανοικτών προτύπων διαλειτουργικότητας στον τομέα της νομοθεσίας.
Μια δική σας εκτίμηση/αξιολόγηση της σπουδαιότητας της ανοικτότητας των δεδομένων…
Ως ερευνητική ομάδα πιστεύουμε πολύ στη σπουδαιότητα και τη σημασία των ανοικτών δεδομένων. Μάλιστα, φέτος όπως και τα προηγούμενα χρόνια έχουμε ανακοινώσει θέματα διπλωματικών εργασιών σε αυτό το πεδίο, ενώ σχεδιάζουμε τη συνέχιση της έρευνας σε διδακτορικό επίπεδο στο πεδίο των ανοικτών διασυνδεδεμένων νομικών δεδομένων. Εκτός από τον οικονομικό αντίκτυπο που μπορεί να έχουν και στον οποίο έχει δοθεί μεγάλη έμφαση από την Ε.Ε, τα ανοικτά δεδομένα συντελούν στην προώθηση της καινοτομίας, αλλά και στη διαφάνεια και τη λογοδοσία στη λειτουργία των κρατικών θεσμών, καθώς και στην ενεργό εμπλοκή των πολιτών στις δημοκρατικές διαδικασίες.
*Ευχαριστούμε θερμά τους κ.κ. Κωνσταντίνο και Αθανάσιο Πλέσσα για την επικοινωνία και τις πληροφορίες που μας έδωσαν και τους ευχόμαστε καλή επιτυχία στο εγχείρημά τους.
**Περισσότερες πληροφορίες για την εφαρμογή μπορεί να αντλήσει όποιος ενδιαφέρεται στο blog του project http://www.openlaws.gr.
